LLMs extracting BIM information adaptively
Is there hope for the lack of standardization? An iterative LLM agent beats static queries on BIM by +37 percentage points. TU Munich proves iteration beats context augmentation and releases ifc-bench v2.

TL;DR
Researchers from TU Munich proved that an LLM agent that writes and executes Python code iteratively over an IFC model beats static query generation by more than 37 percentage points. They also released the largest public BIM-QA benchmark to date, ifc-bench v2 (CC-BY-4.0). For anyone working with BIM and trying to apply AI, it’s required reading — and maybe the signal that we’ve been solving the wrong problem for years.
I recently read a paper that changed how I think about BIM
Researchers from the Technical University of Munich (TU Munich) published a paper on data extraction from BIM models.
Imagine the following scenario, which is probably already yours: the project’s IFC file has 273 thousand entities. Someone asks “what’s the total window area on the south façade?”. Sounds trivial. But the model was built without rules, without a BIM process, the parameters are in Portuguese, and the property you expected is called Empresa: Área útil instead of Width or Area. Good luck with a static query algorithm.
The paper is titled “BIM Information Extraction Through LLM-based Adaptive Exploration” (Hellin, Jang, Fuchs, Nousias, Borrmann), published in 2026 in Automation in Construction. And the way they tackled this problem is what caught my attention.
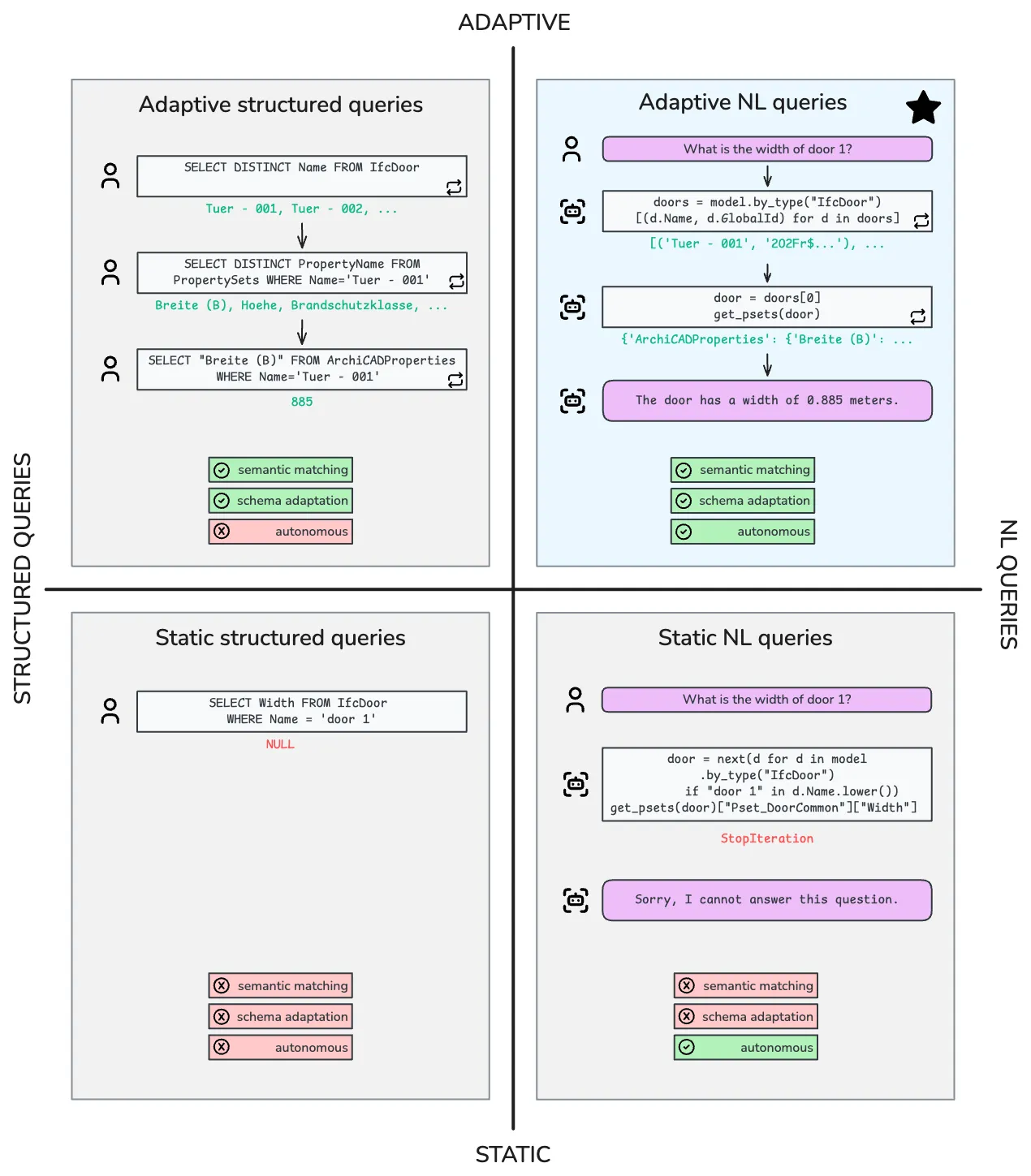
The figure above is the paper’s mind map. Four quadrants, and only one (top right) solves both dimensions of the problem: semantic variation (property names) and structural variation (how the model organizes information).
A heterogeneous IFC model is a polite way of saying we have no standardization at all
The core problem of BIM data extraction isn’t technical. It’s cultural.
IFC models are far too heterogeneous. Each authoring software exports the same property differently. Revit calls it one thing, ArchiCAD another, DDS-CAD yet another. And we know it goes deeper: each user exports the way they see fit, with their own customizations, with parameters they invented in the previous project.
The “door width” property may show up as Width, Rough Width, NominalWidth or Breite (B). Or as a computed geometric attribute, or as a custom property set. IFC versions vary (2X3, 4, 4X3). Models validated with Solibri have a different structure from models exported directly without review.
The classic approach to extraction via code is to write a static query: you assume the structure, write the Python script, run it. When the model’s actual structure doesn’t match what you assumed, the script fails silently or returns wrong data. Even worse when the script works on 9 models in your portfolio and breaks on the tenth.
The question the paper poses is simple and uncomfortable: what if the agent discovered the structure in real time, instead of assuming it?
The agent stopped assuming and started discovering
The researchers’ solution: an LLM agent that writes and executes Python code iteratively over the IFC model, reads the terminal feedback, and adapts the strategy cycle by cycle.
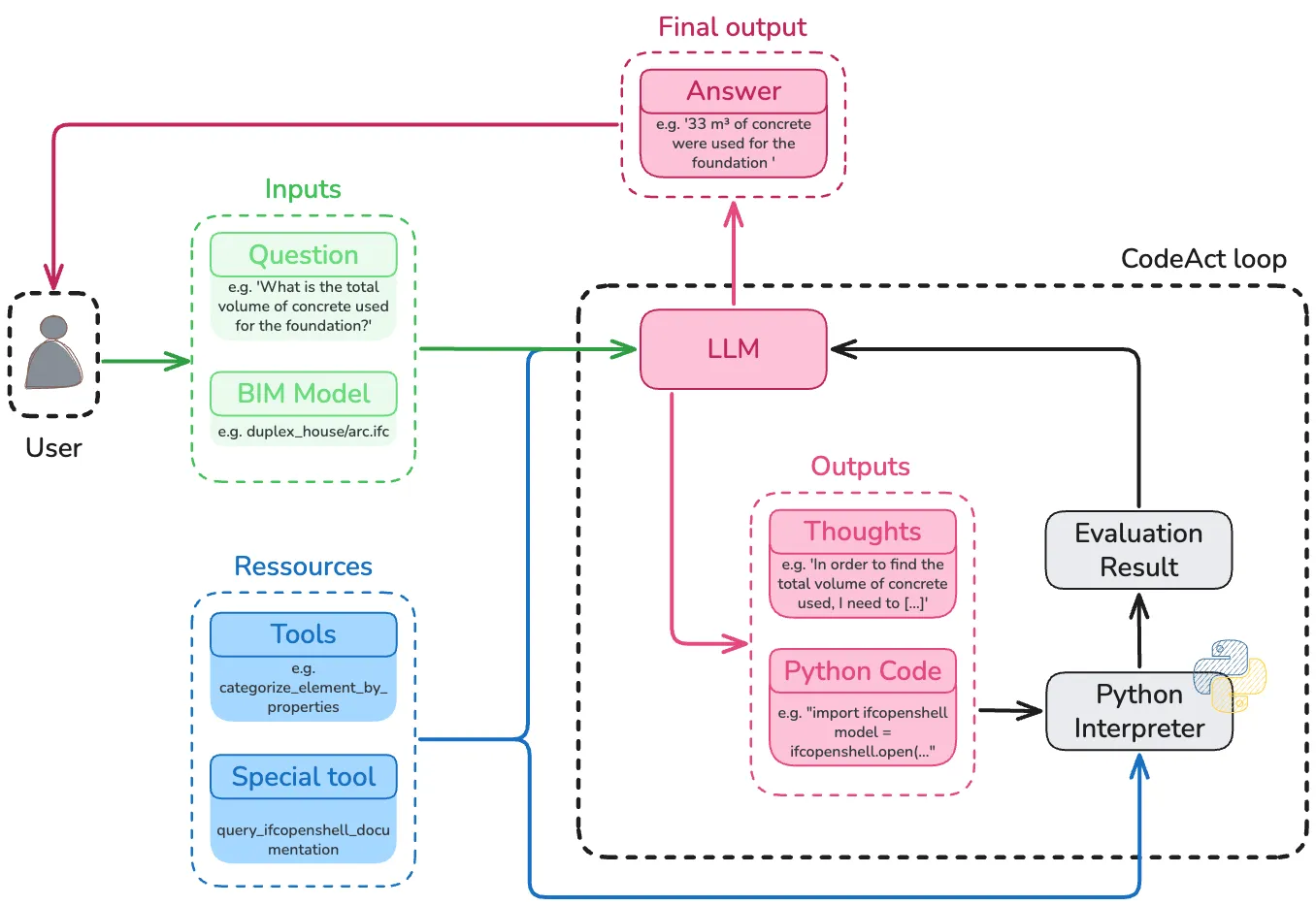
It’s not magic. It’s a CodeAct architecture applied to BIM. The agent doesn’t assume it knows where the information is. It explores, discovers, corrects. Instead of presuming the structure, it discovers it.
The experiment was set up like this:
- 3 paradigms compared: Adaptive-4.7 (iterative, larger model), Adaptive-4.5 Air (iterative, model 2.7x smaller), Static-4.7 (single code generation, no iteration).
- 4 context augmentation strategies: none, IfcOpenShell documentation retrieved via RAG, manual tools, auto-generated tools.
- Custom benchmark: ifc-bench v2, with 1,027 question-answer pairs over 37 IFC models from 21 real projects, released under CC-BY-4.0 on HuggingFace.
The elegance of the setup lies in isolating the “iteration” variable from the “context augmentation” variable. They wanted to know: what matters more, giving the agent more tools, or letting the agent iterate?
The numbers that made me stop and think
Iteration beats context augmentation by an order of magnitude.
The jump from iterative vs. static was +36.8 to 38.5 percentage points (p<0.001). That’s absurd. For context: the best context augmentation effect observed in the entire paper was +4.9pp (documentation helping weaker models). The paradigm gap is nearly 8x larger than the best context augmentation gain.
Translation: it’s no use giving more documentation, RAG, or tools to an agent that generates code only once. What matters is whether it can iterate.
Strong models are indifferent to context augmentation.
The larger model (GLM 4.7) varied only between 55.4% and 56.6% accuracy across the 4 context augmentation strategies. A 1.2pp difference. Statistically insignificant (p>0.8).
The smaller model (GLM 4.5 Air) benefited from documentation (+4.9pp), but was hurt by manual tools (-10.2pp). Manual tools encode assumptions about structure. When the real BIM model’s structure doesn’t match those assumptions, the agent gets stuck on a wrong path.
The hardest category was where the new process stood out the most.
Geometric computation (calculating the area of windows on a façade, for example) was expected to be the hardest category. In the static paradigm, indeed it was: 5.3% accuracy. But in the adaptive paradigm, it jumped to 66.7%, surpassing even direct retrieval (55.6%).
Why does this happen? Because geometry returns a single value. Direct retrieval often requires complete lists, where any missing item fails the entire answer. The adaptive agent can verify and correct iteratively.
The abstention rate says a lot about the model’s confusion.
In the static paradigm, the model refused to answer 43% to 55% of the questions. More than half the time it simply didn’t know what to do. In the adaptive paradigm, the rate dropped to 5.8% to 6.8%. Iterative exploration resolves the structural uncertainty that previously led to paralysis.
The benchmark opens a gate that was locked
Before this work, BIM-QA benchmarks were private, small (11 to 99 queries), and had deterministically verifiable questions. ifc-bench v2 changes that landscape:
- 1,027 question-answer pairs
- 37 models from 21 real projects
- 273,333 IFC entities, 1.6 GB of data
- Diverse authoring tools: Revit (2011 to 2025), ArchiCAD (11 to 25), DDS-CAD, Synchro
- IFC versions: 2X3, 4, and 4X3
- Variable quality: models with 0 validation issues to over 4,000
- Formal categories: direct retrieval, aggregation, geometric computation, estimation with incomplete data

Open, reproducible, on HuggingFace. CC-BY-4.0. For the first time, anyone can compare AI approaches for BIM on equal footing.
Sutton’s lesson, empirically confirmed in BIM
The authors explicitly cite Rich Sutton’s “lesson”: methods that leverage general computation outperform methods that encode human knowledge as model capacity grows.
Manual tools and domain-specific documentation are forms of encoding human knowledge. Iterating over execution feedback is general computation. The paper empirically confirms it: for sufficiently capable models, general computation wins.
This resonates with a parallel we’ve already seen on other fronts: sophisticated vector RAG vs simple lexical search (like grep) on large text bases. The trend is the same: the more capable the base model, the less you need sophisticated retrieval, and the more you gain with simple, iterative strategies.
To dig deeper into this topic, I recommend reading this post by Fabio Akita: RAG Está Morto? Contexto Longo, Grep e o Fim do Vector DB Obrigatório.
Three things this paper proves
- Iteration beats context augmentation by ~8x in accuracy impact. An agent that explores in multiple cycles beats an agent with more documentation in a single attempt. Investing in iterative architecture pays more than investing in prompt engineering.
- Manual tools hurt weak models (but not strong ones). Assumptions encoded in tools break under the real heterogeneity of BIM models. Curiously, giving more “help” can get in the way.
- The 56% ceiling still isn’t enough for unsupervised use in critical workflows. The paper is honest about this. We’re on the path, but we haven’t arrived. You can’t use it as a basis for budgets, for example.
How this changes what I do tomorrow
If you’re building BIM data extraction pipelines with AI: explore iterative architectures (CodeAct, agent with execution feedback) instead of single-shot query generation. The paradigm gain is much larger than any prompt engineering or context augmentation.
If you’re choosing which model to use for BIM tasks: a larger model with an iterative approach beats a smaller model with more tools and documentation. Investing in the paradigm pays more than investing in context augmentation.
If you’re evaluating BIM model quality: the paper indicates that models conforming to standards (IDS, mvdXML, validated with Solibri) reduce the lack of standardization that confuses agents. Input model quality matters as much as the agent.
If you want to run the experiments or use the benchmark: ifc-bench v2 is available on HuggingFace and the code on GitHub, both CC-BY-4.0.
For the Ascent context specifically: data extraction from IFC models is a direct use case for what we’re building. The path this paper points to — agents that explore the model’s structure instead of assuming it — aligns with the philosophy we call Localized Intelligent Modeling (MIL): the plugin needs to understand the model in order to act on it intelligently. The expansion of LLM context is what makes it viable for an agent to do this without vector RAG, directly on the model.
Maybe we’ve been solving the wrong problem
This is where my head kept working after closing the PDF.
The AEC industry spent 30 years trying to standardize how to export BIM. IDS, mvdXML, COBie, classification systems, naming conventions. Each a gigantic effort to force everyone to speak the same language. And the result is that heterogeneity remains the number one bottleneck, because every project, every firm, every client has its own rules.
The paper points to a different path: instead of forcing those who produce BIM to standardize, teach those who consume BIM to adapt. Instead of spending energy trying to make the world uniform, spend energy building agents that absorb any standard.
Maybe this is the industry’s turning point. We stop trying to standardize information, and start absorbing whatever standard shows up. It’s not a surrender. It’s recognizing that the BIM standardization problem is a human coordination problem with 30 years of friction, while the adaptive exploration problem is a technical problem being solved in a paper published in 2026.
If that’s confirmed, it changes what Ascent builds, it changes what every civil engineer working with BIM automation needs to study, and it even changes the doctoral thesis of many people finishing next year.