LLMs extraindo informação de BIM de forma adaptativa
Temos esperança para falta de padronização? Agente LLM iterativo bate query estática em BIM por +37 pontos percentuais. TU Munich prova que iteração vence reforço de contexto e libera o ifc-bench v2.

TL;DR
Pesquisadores da TU Munich provaram que um agente LLM que escreve e executa código Python iterativamente sobre um modelo IFC bate a geração estática de queries em mais de 37 pontos percentuais. Eles também abriram o maior benchmark público de BIM-QA até hoje, o ifc-bench v2 (CC-BY-4.0). Para quem trabalha com BIM e tenta aplicar IA, é leitura obrigatória, e talvez seja o sinal de que estamos resolvendo o problema errado há anos.
Esses dias eu li um paper que mudou o que eu penso sobre BIM
Pesquisadores da Universidade Técnica de Munique (TU Munich) publicaram um sobre extração de dados em modelos BIM.
Imagina o seguinte cenário, que provavelmente já é o teu: o arquivo IFC do projeto tem 273 mil entidades. Alguém pergunta “qual a área total de janelas na fachada sul?”. Parece trivial. Mas o modelo foi feito sem regras, sem processo BIM, os parâmetros estão em português, e a propriedade que você esperava se chama Empresa: Área útil em vez de Width ou Área. Boa sorte com um algoritmo de consulta estático ou query estática.
O paper se chama “BIM Information Extraction Through LLM-based Adaptive Exploration” (Hellin, Jang, Fuchs, Nousias, Borrmann), publicado em 2026 na Automation in Construction. E o jeito que eles atacaram esse problema é o que me chamou atenção.
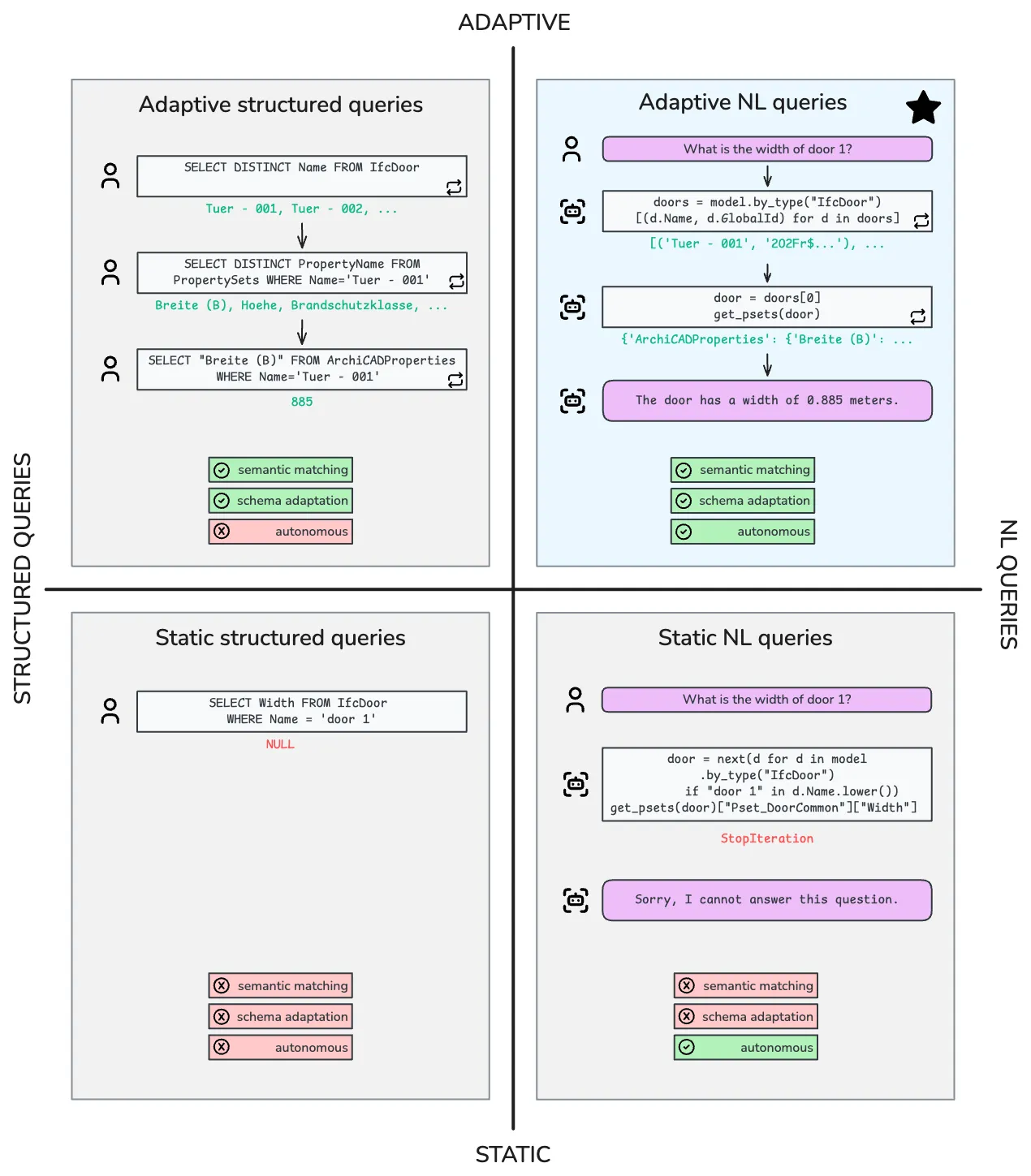
A figura acima é o mapa mental do paper. Quatro quadrantes, e só um (canto superior direito) resolve as duas dimensões do problema: variação semântica (nomes de propriedades) e variação estrutural (como o modelo organiza a informação).
Modelo IFC heterogêneo é uma forma polida de dizer que não temos nenhum nível de padronização
O problema central da extração de dados em BIM não é técnico. É cultural.
Modelos IFC são heterogêneos demais. Cada software de autoria exporta a mesma propriedade de jeito diferente. Revit chama de uma coisa, ArchiCAD de outra, DDS-CAD de outra. Sabemos também que o buraco é mais embaixo: cada usuário exporta do jeito que bem entende, com as customizações dele, com os parâmetros que ele inventou no projeto anterior.
A propriedade “largura de porta” pode aparecer como Width, Rough Width, NominalWidth ou Breite (B). Ou como atributo geométrico calculado, ou como property set customizada. Versões IFC variam (2X3, 4, 4X3). Modelos validados com Solibri têm estrutura diferente de modelos exportados direto sem revisão.
A abordagem clássica para extração via código é escrever query estática: você presume a estrutura, escreve o script Python, roda. Quando a estrutura real do modelo não bate com o que você presumiu, o script falha silenciosamente ou devolve dado errado. Pior ainda quando o script funciona em 9 modelos do teu portfólio e quebra no décimo.
A pergunta que o paper coloca é simples e desconfortável: e se o agente descobrisse a estrutura em tempo real, em vez de presumir?
O agente parou de presumir e começou a descobrir
A solução dos pesquisadores: um agente LLM que escreve e executa código Python iterativamente sobre o modelo IFC, lê o feedback do terminal, e adapta a estratégia ciclo por ciclo.
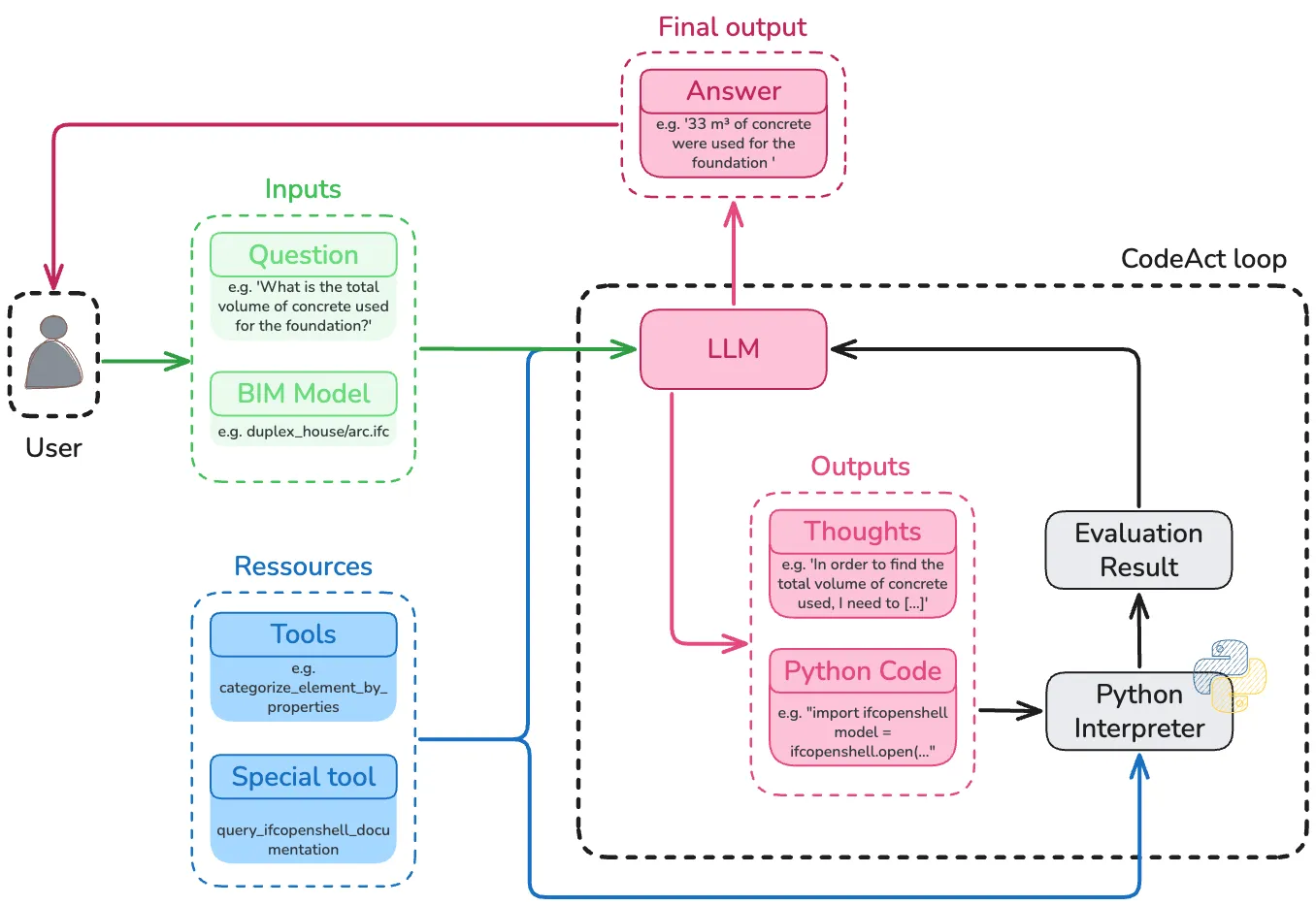
Não é mágica. É uma arquitetura CodeAct aplicada a BIM. O agente não presume que sabe onde a informação está. Ele explora, descobre, corrige. Em vez de presumir a estrutura, ele descobre.
O experimento foi montado assim:
- 3 paradigmas comparados: Adaptive-4.7 (iterativo, modelo maior), Adaptive-4.5 Air (iterativo, modelo 2,7x menor), Static-4.7 (geração única de código, sem iteração).
- 4 estratégias de adição de contexto: nenhuma, documentação da IfcOpenShell recuperada via RAG, ferramentas manuais, ferramentas auto-geradas.
- Benchmark próprio: ifc-bench v2, com 1.027 pares pergunta-resposta sobre 37 modelos IFC de 21 projetos reais, publicado em CC-BY-4.0 no HuggingFace.
A elegância do setup está em isolar a variável “iteração” da variável “adição de contexto”. Eles queriam saber: o que importa mais, dar mais ferramentas ao agente, ou deixar o agente iterar?
Os números que me fizeram parar pra pensar
Iteração bate reforço de contexto por uma ordem de magnitude.
O salto de iterativo vs. estático foi de +36,8 a 38,5 pontos percentuais (p<0,001). Isso é absurdo. Para contexto: o melhor efeito de adição de contexto observado no paper inteiro foi de +4,9pp (documentação ajudando modelos mais fracos). O gap de paradigma é quase 8x maior que o melhor ganho de reforço de contexto.
Traduzindo: não adianta dar mais documentação, RAG ou ferramentas a um agente que gera código uma única vez. O que importa é se ele consegue iterar.
Modelos fortes são indiferentes ao reforço de contexto.
O modelo maior (GLM 4.7) variou apenas 55,4% a 56,6% de acurácia entre as 4 estratégias de adição de contexto. Diferença de 1,2pp. Estatisticamente insignificante (p>0,8).
O modelo menor (GLM 4.5 Air) se beneficiou de documentação (+4,9pp), mas foi prejudicado por ferramentas manuais (-10,2pp). Ferramentas manuais codificam pressupostos sobre estrutura. Quando a estrutura do modelo BIM real não casa com esses pressupostos, o agente fica preso num caminho errado.
A categoria mais difícil foi onde o novo processo se destacou.
Computação geométrica (calcular área de janelas numa fachada, por exemplo) era esperado ser a categoria mais dura. No paradigma estático, de fato era: 5,3% de acurácia. Mas no adaptativo, saltou para 66,7%, ultrapassando até recuperação direta (55,6%).
Por que isso acontece? Porque geometria retorna um único valor. Já recuperação direta frequentemente exige listas completas, onde qualquer item faltando falha a resposta inteira. O agente adaptativo consegue verificar e corrigir iterativamente.
A taxa de abstenção conta muito sobre a confusão do modelo.
No estático, o modelo se recusou a responder em 43% a 55% das questões. Mais da metade do tempo ele simplesmente não sabia o que fazer. No adaptativo, a taxa caiu para 5,8% a 6,8%. Exploração iterativa resolve a incerteza estrutural que antes levava à paralisia.
O benchmark abre a porteira que estava trancada
Antes desse trabalho, os benchmarks de BIM-QA eram privados, pequenos (11 a 99 consultas) e com perguntas deterministicamente verificáveis. O ifc-bench v2 muda esse cenário:
- 1.027 pares pergunta-resposta
- 37 modelos de 21 projetos reais
- 273.333 entidades IFC, 1,6 GB de dados
- Ferramentas de autoria diversas: Revit (2011 a 2025), ArchiCAD (11 a 25), DDS-CAD, Synchro
- Versões IFC: 2X3, 4 e 4X3
- Qualidade variável: modelos com 0 issues de validação até mais de 4.000
- Categorias formais: recuperação direta, agregação, computação geométrica, estimação com dados incompletos

Aberto, reproduzível, no HuggingFace. CC-BY-4.0. Pela primeira vez, qualquer pessoa pode comparar abordagens de IA para BIM em pé de igualdade.
A lesson de Sutton, confirmada empiricamente em BIM
Os autores citam explicitamente a “lesson” de Rich Sutton: métodos que alavancam computação geral superam métodos que codificam conhecimento humano conforme a capacidade do modelo aumenta.
Ferramentas manuais e documentação específica de domínio são formas de codificar conhecimento humano. Iteração sobre feedback de execução é computação geral. O paper empiricamente confirma: para modelos com capacidade suficiente, computação geral vence.
Isso ressoa com um paralelo que a gente já viu em outras frentes: RAG vetorial sofisticado contra busca lexical simples (tipo grep) em bases grandes de texto. A tendência é a mesma: quanto mais capaz o modelo de base, menos você precisa de retrieval sofisticado e mais você ganha com estratégias simples e iterativas.
Para entender mais sobre esse tema recomendo ler esse post do Fabio Akita: RAG Está Morto? Contexto Longo, Grep e o Fim do Vector DB Obrigatório.
Três coisas que esse paper prova
- Iteração vence reforço de contexto por ~8x em impacto de acurácia. Agente que explora em múltiplos ciclos bate agente com mais documentação numa única tentativa. Investir em arquitetura iterativa rende mais que investir em prompt engineering.
- Ferramentas manuais prejudicam modelos fracos (mas não modelos fortes). Pressupostos codificados em ferramentas quebram na heterogeneidade real dos modelos BIM. Curiosamente, dar mais “ajuda” pode atrapalhar.
- O teto de 56% ainda não é suficiente para uso não supervisionado em workflows críticos. O paper é honesto sobre isso. Estamos no caminho, mas não chegamos. Não dá pra usar como base de orçamentos por exemplo.
Como isso muda o que eu faço amanhã
Se você está construindo pipelines de extração de dados BIM com IA: explore arquiteturas iterativas (CodeAct, agente com feedback de execução) em vez de geração única de query. O ganho de paradigma é muito maior que qualquer engenharia de prompt ou reforço de contexto.
Se você está escolhendo qual modelo usar para tarefas BIM: um modelo maior com abordagem iterativa bate um modelo menor com mais ferramentas e documentação. Vale mais investir no paradigma do que na adição de contexto.
Se você está avaliando qualidade de modelos BIM: o paper indica que modelos conformes a padrões (IDS, mvdXML, validados com Solibri) reduzem a falta de padronização que confunde os agentes. Qualidade do modelo de entrada importa tanto quanto o agente.
Se você quer rodar os experimentos ou usar o benchmark: o ifc-bench v2 está disponível no HuggingFace e o código no GitHub, ambos CC-BY-4.0.
Para o contexto Ascent especificamente: a extração de dados de modelos IFC é caso de uso direto pra o que estamos construindo. O caminho que esse paper aponta, de agentes que exploram a estrutura do modelo em vez de presumir, é alinhado com a filosofia que chamamos de Modelagem Inteligente Localizada (MIL): o plugin precisa entender o modelo para agir sobre ele de forma inteligente. A expansão de contexto dos LLMs é o que torna viável um agente fazer isso sem RAG vetorial, direto no modelo.
Talvez a gente esteja resolvendo o problema errado
Aqui é onde minha cabeça ficou trabalhando depois de fechar o PDF.
A indústria AEC gastou 30 anos tentando padronizar como exportar BIM. IDS, mvdXML, COBie, classification systems, naming conventions. Cada esforço gigantesco para forçar todo mundo a falar a mesma língua. E o resultado é que a heterogeneidade continua sendo o gargalo número um, porque cada projeto, cada escritório, cada cliente tem suas regras.
O paper aponta um caminho diferente: em vez de forçar quem produz BIM a padronizar, ensinar quem consome BIM a se adaptar. Em vez de gastar energia tentando uniformizar o mundo, gastar energia construindo agentes que absorvem qualquer padrão.
Talvez seja essa a virada do setor. Paramos de tentar padronizar a informação, e começamos a absorver qualquer padrão que aparecer. Não é uma rendição. É reconhecer que o problema da padronização BIM é um problema de coordenação humana com 30 anos de fricção, enquanto o problema da exploração adaptativa é um problema técnico que está sendo resolvido em paper publicado em 2026.
Se isso se confirmar, muda o que a Ascent constrói, muda o que cada engenheiro civil que mexe com automação BIM precisa estudar, e muda inclusive a tese de doutorado de muita gente que está terminando ano que vem.